Po wydaniu przez OpenAI modelu o1, tzw. modelu rozumowania, nastąpiła eksplozja modeli rozumowania z konkurencyjnych laboratoriów AI. Na początku listopada firma badawcza DeepSeek, finansowana przez traderów ilościowych, uruchomiła podgląd swojego pierwszego algorytmu rozumowania, DeepSeek-R1. W tym samym miesiącu zespół Qwen z Alibaba zaprezentował to, co twierdzi, że jest pierwszym „otwartym” konkurentem dla o1.
Co więc otworzyło te wrota? Cóż, po pierwsze, poszukiwanie nowych podejść do udoskonalania technologii generatywnej AI. Jak niedawno donosił mój kolega Max Zeff, techniki „brute force” do skalowania modeli nie przynoszą już takich ulepszeń, jak kiedyś.
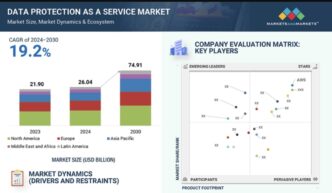
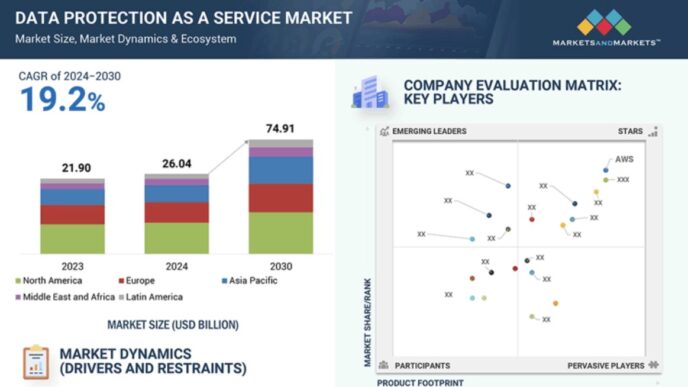
Na firmy AI wywierana jest intensywna presja konkurencyjna, aby utrzymać obecne tempo innowacji. Według jednego z szacunków, globalny rynek AI osiągnął wartość 196,63 miliarda dolarów w 2023 roku i może być wart 1,81 biliona dolarów do 2030 roku. 
OpenAI twierdzi, że modele rozumowania mogą „rozwiązywać trudniejsze problemy” niż wcześniejsze modele i stanowią krok naprzód w rozwoju generatywnej AI. Jednak nie wszyscy są przekonani, że modele rozumowania są najlepszą drogą naprzód.
Ameet Talwalkar, profesor nadzwyczajny uczenia maszynowego na Carnegie Mellon, mówi, że uważa początkową grupę modeli rozumowania za „dość imponującą”. Jednak w tym samym oddechu powiedział mi, że „kwestionowałby motywy” każdego, kto z pewnością twierdzi, że wie, jak daleko modele rozumowania zabiorą przemysł.
„Firmy AI mają finansowe motywacje, aby oferować różowe prognozy dotyczące możliwości przyszłych wersji swojej technologii” – powiedział Talwalkar. „Ryzykujemy, że skupimy się myopatycznie na jednym paradygmacie — dlatego tak ważne jest, aby szersza społeczność badawcza AI unikała ślepego wierzenia w szum i działania marketingowe tych firm, a zamiast tego skupiała się na konkretnych wynikach”.
Dwie wady modeli rozumowania to (1) ich kosztowność i (2) energochłonność.
Na przykład w API OpenAI firma pobiera opłatę w wysokości 15 dolarów za każde ~750 000 słów analizowanych przez o1 i 60 dolarów za każde ~750 000 słów generowanych przez model. To od 3 do 4 razy więcej niż koszt najnowszego modelu „bez rozumowania” OpenAI, GPT-4o.
O1 jest dostępny w platformie czatowej OpenAI zasilanej AI, ChatGPT, za darmo — z ograniczeniami. Ale na początku tego miesiąca OpenAI wprowadziło bardziej zaawansowany poziom o1, tryb o1 pro, który kosztuje oszałamiające 2400 dolarów rocznie.
„Ogólny koszt [dużego modelu językowego] rozumowania z pewnością nie spada” – powiedział Guy Van Den Broeck, profesor informatyki na UCLA, w rozmowie z TechCrunch.
Jednym z powodów, dla których modele rozumowania są tak kosztowne, jest to, że wymagają dużych zasobów obliczeniowych do działania. W przeciwieństwie do większości AI, o1 i inne modele rozumowania próbują sprawdzać swoją pracę w trakcie jej wykonywania. Pomaga im to unikać niektórych pułapek, które zwykle potykają modele, z wadą polegającą na tym, że często zajmuje im więcej czasu, aby dojść do rozwiązań.
OpenAI przewiduje, że przyszłe modele rozumowania będą „myśleć” przez godziny, dni, a nawet tygodnie. Firma przyznaje, że koszty użytkowania będą wyższe, ale korzyści — od przełomowych baterii po nowe leki na raka — mogą być tego warte.
Wartość dzisiejszych modeli rozumowania jest mniej oczywista. Costa Huang, badacz i inżynier uczenia maszynowego w organizacji non-profit Ai2, zauważa, że o1 nie jest bardzo niezawodnym kalkulatorem. A pobieżne wyszukiwania w mediach społecznościowych ujawniają szereg błędów w trybie o1 pro.
„Te modele rozumowania są wyspecjalizowane i mogą nie działać dobrze w ogólnych dziedzinach” – powiedział Huang w rozmowie z TechCrunch. „Niektóre ograniczenia zostaną pokonane szybciej niż inne”.
Van den Broeck twierdzi, że modele rozumowania nie wykonują rzeczywistego rozumowania i dlatego są ograniczone w rodzajach zadań, które mogą skutecznie rozwiązywać. „Prawdziwe rozumowanie działa na wszystkich problemach, nie tylko na tych, które są prawdopodobne [w danych treningowych modelu]” – powiedział. „To jest główne wyzwanie, które wciąż trzeba pokonać”.
Biorąc pod uwagę silną motywację rynkową do zwiększenia modeli rozumowania, można bezpiecznie założyć, że z czasem będą się one poprawiać. W końcu nie tylko OpenAI, DeepSeek i Alibaba inwestują w tę nową linię badań AI. VC i założyciele z pokrewnych branż skupiają się wokół idei przyszłości zdominowanej przez AI rozumowania.
Jednak Talwalkar obawia się, że duże laboratoria będą strzegły tych ulepszeń.
„Duże laboratoria mają zrozumiałe powody konkurencyjne, aby pozostać tajemniczymi, ale ten brak przejrzystości poważnie utrudnia społeczności badawczej możliwość angażowania się w te pomysły” – powiedział. „W miarę jak więcej osób pracuje w tym kierunku, spodziewam się, że [modele rozumowania] szybko się rozwiną. Ale chociaż niektóre pomysły będą pochodzić z akademii, biorąc pod uwagę tutaj motywacje finansowe, spodziewałbym się, że większość — jeśli nie wszystkie — modele będą oferowane przez duże laboratoria przemysłowe, takie jak OpenAI.”