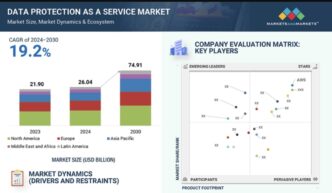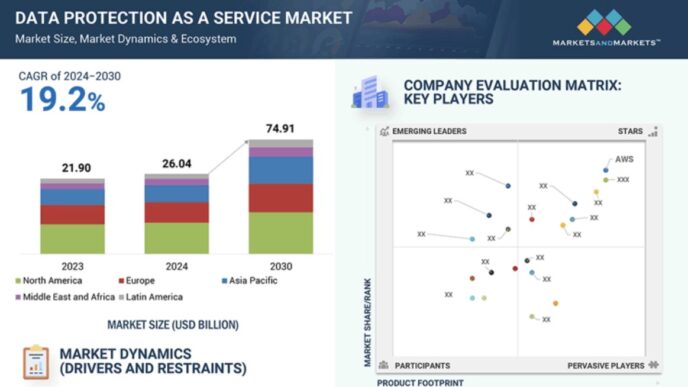
Alibaba ogłosiła Marco-o1, duży model językowy (LLM) zaprojektowany do rozwiązywania zarówno konwencjonalnych, jak i otwartych zadań problemowych.
Marco-o1, stworzony przez zespół MarcoPolo Alibaby, stanowi kolejny krok naprzód w zdolności AI do radzenia sobie z złożonymi wyzwaniami rozumowania — szczególnie w matematyce, fizyce, kodowaniu i obszarach, gdzie mogą brakować jasnych standardów.
Opierając się na postępach w rozumowaniu OpenAI z modelem o1, Marco-o1 wyróżnia się poprzez włączenie kilku zaawansowanych technik, w tym dostrajania Chain-of-Thought (CoT), Monte Carlo Tree Search (MCTS) i nowych mechanizmów refleksji. Te komponenty współpracują, aby zwiększyć zdolności modelu do rozwiązywania problemów w różnych dziedzinach. 
Zespół deweloperski wdrożył kompleksową strategię dostrajania przy użyciu wielu zbiorów danych, w tym przefiltrowanej wersji Open-O1 CoT Dataset, syntetycznego Marco-o1 CoT Dataset i specjalistycznego Marco Instruction Dataset. W sumie korpus treningowy składa się z ponad 60 000 starannie wyselekcjonowanych próbek.
Model wykazał szczególnie imponujące wyniki w zastosowaniach wielojęzycznych. W testach Marco-o1 osiągnął znaczące poprawy dokładności o 6,17% na angielskim zbiorze danych MGSM i 5,60% na jego chińskim odpowiedniku. Model wykazał szczególną siłę w zadaniach tłumaczeniowych, zwłaszcza przy obsłudze wyrażeń potocznych i niuansów kulturowych.
Jedną z najbardziej innowacyjnych cech modelu jest jego implementacja zmiennych ziarnistości działań w ramach MCTS. To podejście pozwala modelowi eksplorować ścieżki rozumowania na różnych poziomach szczegółowości, od szerokich kroków po bardziej precyzyjne „mini-kroki” składające się z 32 lub 64 tokenów. Zespół wprowadził również mechanizm refleksji, który skłania model do samooceny i ponownego rozważenia swojego rozumowania, co prowadzi do poprawy dokładności w złożonych scenariuszach rozwiązywania problemów.
Integracja MCTS okazała się szczególnie skuteczna, a wszystkie wersje modelu wzbogacone o MCTS wykazały znaczące poprawy w porównaniu z bazową wersją Marco-o1-CoT. Eksperymenty zespołu z różnymi ziarnistościami działań ujawniły interesujące wzorce, choć zauważają, że określenie optymalnej strategii wymaga dalszych badań i bardziej precyzyjnych modeli nagród.
Zespół deweloperski był transparentny w kwestii obecnych ograniczeń modelu, przyznając, że choć Marco-o1 wykazuje silne cechy rozumowania, wciąż nie jest w pełni zrealizowanym modelem „o1”. Podkreślają, że to wydanie reprezentuje ciągłe zaangażowanie w doskonalenie, a nie gotowy produkt.
Patrząc w przyszłość, zespół Alibaby ogłosił plany włączenia modeli nagród, w tym Outcome Reward Modeling (ORM) i Process Reward Modeling (PRM), aby zwiększyć zdolności decyzyjne Marco-o1. Badają również techniki uczenia się przez wzmocnienie, aby dalej doskonalić zdolności modelu do rozwiązywania problemów.
Model Marco-o1 i powiązane zbiory danych zostały udostępnione społeczności badawczej za pośrednictwem repozytorium GitHub Alibaby, wraz z kompleksową dokumentacją i przewodnikami implementacyjnymi. Wydanie obejmuje instrukcje instalacji i przykładowe skrypty zarówno do bezpośredniego użycia modelu, jak i wdrożenia za pośrednictwem FastAPI.